![]()
Сегодня, хотелось бы чуточку подробнее поговорить о вскользь упомянутой в предыдущей статье о критериях выбора винчестера технологии SMART, а также выяснить вопрос о появлении плохих секторов при проверке поверхности специальными программами и исчерпании резервной поверхности для их переназначения - вопросу, поднятому на форуме из прошлой статьи.
Для начала как всегда краткий исторический экскурс. Надежность жесткого диска (и любого устройства хранения в самом общем случае) всегда придается огромное значение. И дело отнюдь не в его стоимости, а в ценности той информации, которую он уносит с собой в мир иной, уходя из жизни сам, и в потерях прибыли, связанных с простоями при выходе из строя винчестеров, если речь идет о бизнес-пользователях, даже в том случае, если информация осталась. И вполне естественно, что о таких неприятных моментах хочется знать заранее. Даже обычные рассуждения на бытовом уровне подсказывают, что наблюдение за состоянием прибора в работе, может подсказать такие моменты. Осталось только каким-то образом реализовать это наблюдение в винчестере.
Впервые над этой задачей задумались инженеры голубого гиганта (IBM то бишь). И в 1995 году они предложили технологию, отслеживающую несколько критически важных параметров накопителя, и делающую попытки на основании собранных данных предсказать выход его из строя - Predictive Failure Analysis (PFA). Идею подхватила Compaq, которая чуть позже создала свою технологию - IntelliSafe. В разработке Compaq также поучаствовали Seagate, Quantum и Conner. Созданная ими технология также отслеживала ряд рабочих характеристик диска, сравнивала их с допустимым значением и рапортовала хост-системе в случае наличия опасности. Это был огромный шаг вперед если и не в повышении надежности винчестеров, то хотя бы в уменьшении риска потери информации при их использовании. Первые попытки оказались удачными, и показали необходимость дальнейшего развития технологии. Уже в объединении всех крупных производителей жестких дисков появилась технология S.M.A.R.T (Self Monitoring Analysing and Reporting Technology), базирующаяся на технологиях IntelliSafe и PFA (кстати говоря, PFA существует и поныне, как набор технологий для наблюдения и анализа за различными подсистемами серверов IBM, в том числе и дисковой подсистемой, причем наблюдение за последней базируется именно на технологии SMART).
Итак, SMART - это технология внутренней оценки состояния диска, и механизм предсказания возможного выхода из строя жесткого диска. Важно отметить то, что технология в принципе не решает возникающих проблем (основные из них показаны на рисунке чуть ниже), она способна лишь предупредить об уже возникшей проблеме либо об ожидающейся в ближайшем времени.
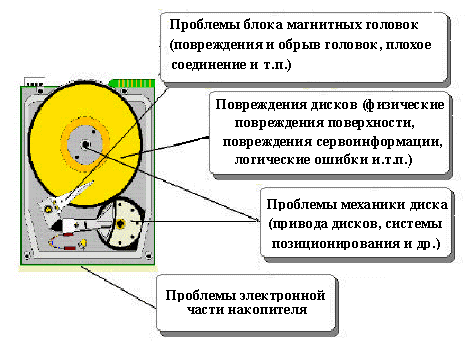
При этом нужно также сказать, что технология не в состоянии предсказать абсолютно все возможные проблемы и это логично: выход электроники в результате скачка напряжения, порча головок и поверхности в результате удара и т.п. никакая технология предсказать не в силах. Предсказуемы лишь те проблемы, которые связаны с постепенным ухудшением каких-либо характеристик, равномерной деградацией каких либо компонент.
В своем развитии технология SMART прошла три этапа. В первом поколении было реализовано наблюдение небольшого числа параметров. Никаких самостоятельных действий накопителя не предусматривалось. Запуск осуществлялся только командами по интерфейсу. Спецификации описывающей стандарт полностью нет, и, следовательно, не было и нет и четкого предначертания, о том, какие именно параметры надлежит контролировать. Более того, их определение и определение допустимого уровня их снижения целиком и полностью предоставлялся производителям винчестеров (что естественно в силу того, что производителю виднее что именно надлежит контролировать данном его винчестере, ибо все винчестеры слишком различны). И программное обеспечение, по этой причине, написанное, как правило, сторонними фирмами, не было универсальным, и могло ошибочно рапортовать о предстоящем сбое (путаница возникала из-за того, что под одним и тем же идентификатором различные производители хранили значения различных параметров). Имело место большое число жалоб на то, что число случаев обнаружения пред сбойного состояния чрезвычайно мало (особенности человеческой природы: получать хочется все и сразу, жаловаться на внезапные отказы дисков до внедрения SAMRT в голову как-то никому не приходило). Ситуация усугубилась еще и тем, что в большинстве случаев не были выполнены минимально необходимые требования для функционирования SMART (об этом поговорим позже). Статистика говорит о том, что число предсказываемых сбоев было менее 20%. Технология на этом этапе была далека от совершенства, но являлась революционным шагом вперед.
О втором этапе развития SMART - SMART II известно также не много. В основном наблюдались те же проблемы, что и с первой. Нововведениями являлись возможность фоновой проверки поверхности, выполняемая диском в автоматическом режиме при простоях и ведение журналов ошибок, расширился список контролируемых параметров (снова же в зависимости от модели и производителя). Статистика говорит о том, что число предсказываемых сбоев достигло 50%.
Современный этап представлен технологией SMART III. На ней остановимся подробней, попытаемся разобраться в общих чертах как она работает, что и зачем в ней нужно.
Нам уже известно, что SMART производит наблюдение за основными характеристиками накопителя. Эти параметры называются атрибутами. Необходимые к мониторингу параметры определяются производителем. Каждый атрибут имеет какую-то величину - Value. Обычно изменяется в диапазоне от 0 до 100 (хотя может быть в диапазоне до 200 или до 255), ее величина - это надежность конкретного атрибута относительно некоторого его эталонного значения (определяется производителем). Высокое значение говорит об отсутствии изменений данного параметра или, в зависимости от значения, его медленном ухудшении. Низкое значение говорит о быстрой деградации или о возможном скором сбое, т.е. чем выше значение Value атрибута, тем лучше. Некоторыми программами мониторинга выводится значение Raw или Raw Value - это значение атрибута во внутреннем формате (который так же различен у дисков разных моделей и разных производителей), в том, в котором он хранится в накопителе. Для простого пользователя он малоинформативен, больший интерес представляет посчитанное из него значение Value. Для каждого атрибута производителем определяется минимальное возможное значение, при котором гарантируется безотказная работа накопителя - Threshold. При значении атрибута ниже величины Threshold очень вероятен сбой в работе или полный отказ. Осталось только добавить, что атрибуты бывают критически важными и некритически. Выход критически важного параметра за пределы Threshold фактический означает выход из строя, выход за переделы допустимых значений некритически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность (хотя, возможно, с некоторым ухудшением некоторых характеристик: производительности например).
К наиболее часто наблюдаемым критически важным характеристикам относятся: Raw Read Error Rate - частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time - время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе. Не ухудшающееся немаксимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например блок питания подкачал.
Spin Up Retry Count - число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно немаксимальное Value) свидетельствует о проблемах в механической части накопителя.
Seek Error Rate - частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count - число операций переназначения секторов. SMART в современных способен произвести анализ сектора на стабильность работы "на лету" и в случае признания его сбойным произвести его переназначение. Ниже мы поговорим об этом подробнее.
Из некритических, так сказать информационных атрибутов, обычно производят наблюдение за следующими:
Все происходящие ошибки и изменения параметров фиксируются в журналах SMART. Эта возможность появилась уже в SMART II. Все параметры журналов - назначение, размер, их число определяются изготовителем винчестера. Нас с вами в настоящий момент интересует только факт их наличия. Без подробностей. Информация хранящаяся в журналах используется для анализа состояния и составления прогнозов.
Если не вдаваться в подробности, то работа SMART проста - при работе накопителя просто отслеживаются все возникающие ошибки и подозрительные явления, которые находят отражение в соответствующих атрибутах. Кроме того начиная так же со SMART II у многих накопителей появились функции самодиагностики. Запуск тестов SMART возможен в двух режимах, off-line - тест выполняется фактически в фоновом режиме, так как накопитель в любое время готов принять и выполнить команду, и монопольном при котором при поступлении команды, выполнение теста завершается.
Документировано существует три типа тестов самодиагностики: фоновый сбор данных (Off-line collection), сокращенный тест (Short Self-test), расширенный тест (Extended Self-test). Два последних способны выполняться как в фоновом, так и в монопольном режимах. Набор тестов в них входящих не стандартизирован.
Продолжительность их выполнения может быть от секунд до минут и часов. Если вы вдруг не обращаетесь к диску, а он при этом издатет звуки как и при рабочей нагрузке - он просто похоже занимается самоанализом. Все данные собранне в результате таких тестов будут также сохранены в журналах и аттрибутах.
Теперь вернемся к вопросу бэд-секторов, с которых все началось. В SMART III появилась функция, позволяющая прозрачно для пользователя переназначать BAD сектора. Работает механизм достаточно просто, при неустойчивом чтении сектора, или же ошибки его чтения, SMART заносит его в список нестабильных и увеличит их счетчик (Current Pending Sector Count). Если при повторном обращении сектор будет прочитан без проблем, он будет выброшен из этого списка. Если же нет, то при предоставившейся возможности - при отсутствии обращений к диску, диск начнет самостоятельную проверку поверхности, в первую очередь подозрительных секторов. Если сектор будет признан сбойным, то он будет переназначен на сектор из резервной поверхности (соответственно RSC увеличиться). Такое фоновое переназначение приводит к тому, что на современных винчестерах сбойные секторы практически никогда не видны при проверке поверхности сервисными программами. В тоже время, при большом числе плохих секторов их переназначение не может происходить до бесконечности. Первый ограничитель очевиден - это объем резервной поверхности. Именно этот случай я имел ввиду. Второй не столь очевиден - дело в том, что у современных винчестеров есть два дефект-листа P-list (Primary, заводской) и G-list (Growth, формируется непосредственно во время эксплуатации). И при большом числе переназначений может оказаться так, что в G-list не оказывается места для записи о новом переназначении. Эта ситуация может быть выявлена по высокому показателю переназначенных секторов в SMART. В этом случае еще не все потеряно, но это выходит за рамки данной статьи.
Итак, используя данные SMART даже не нося диск в мастерскую можно довольно точно сказать, что с ним происходит. Существуют различные технологии-надстройки над SMART, которые позволяют определить состояние диска еще более точно и практически достоверно причину его неисправности. Об этих технологиях мы поговорим в отдельной статье.
Нужно знать, что приобретения накопителя со SMART не достаточно, для того, что бы быть в курсе всех происходящих с диском проблем. Диск, конечно, может следить за своим состоянием и без посторонней помощи, но он не сможет сам предупредить в случае приближающейся опасности. Нужно что-то, что позволит на основании данных SMART выдать предупреждение. (обычная цепочка приведена на рисунке чуть ниже).

Как вариант возможен BIOS, который при загрузке при включенной соответствующей опции проверяет состояние SMART накопителей. А если же вам хочется вести постоянный контроль за состоянием диска, необходимо использовать какую-то программу мониторинга. Тогда вы сможете видеть информацию в подробном и удобном виде.
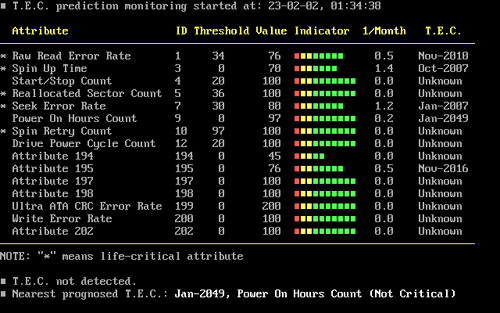
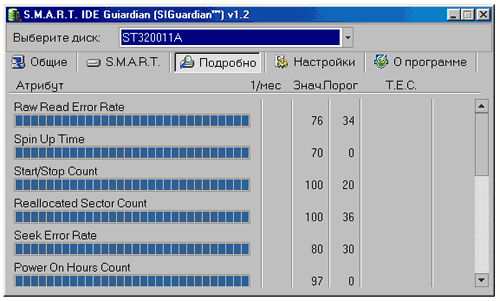
Об этих программах мы также поговорим в отдельной статье. Именно это я имел ввиду, когда говорил о том, что по началу не выполнялись необходимые требования при эксплуатации жестких дисков с SMART .
|
|
|
|

